我们专注于使用人工智能技术对文本、影像数据的处理与理解,为用户提升其生产力和决策能力。
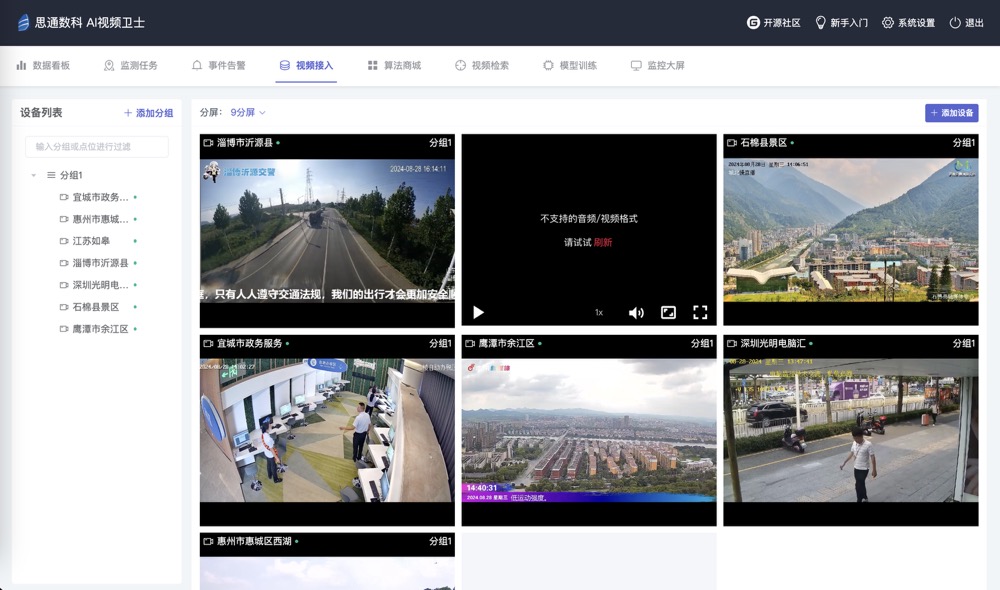
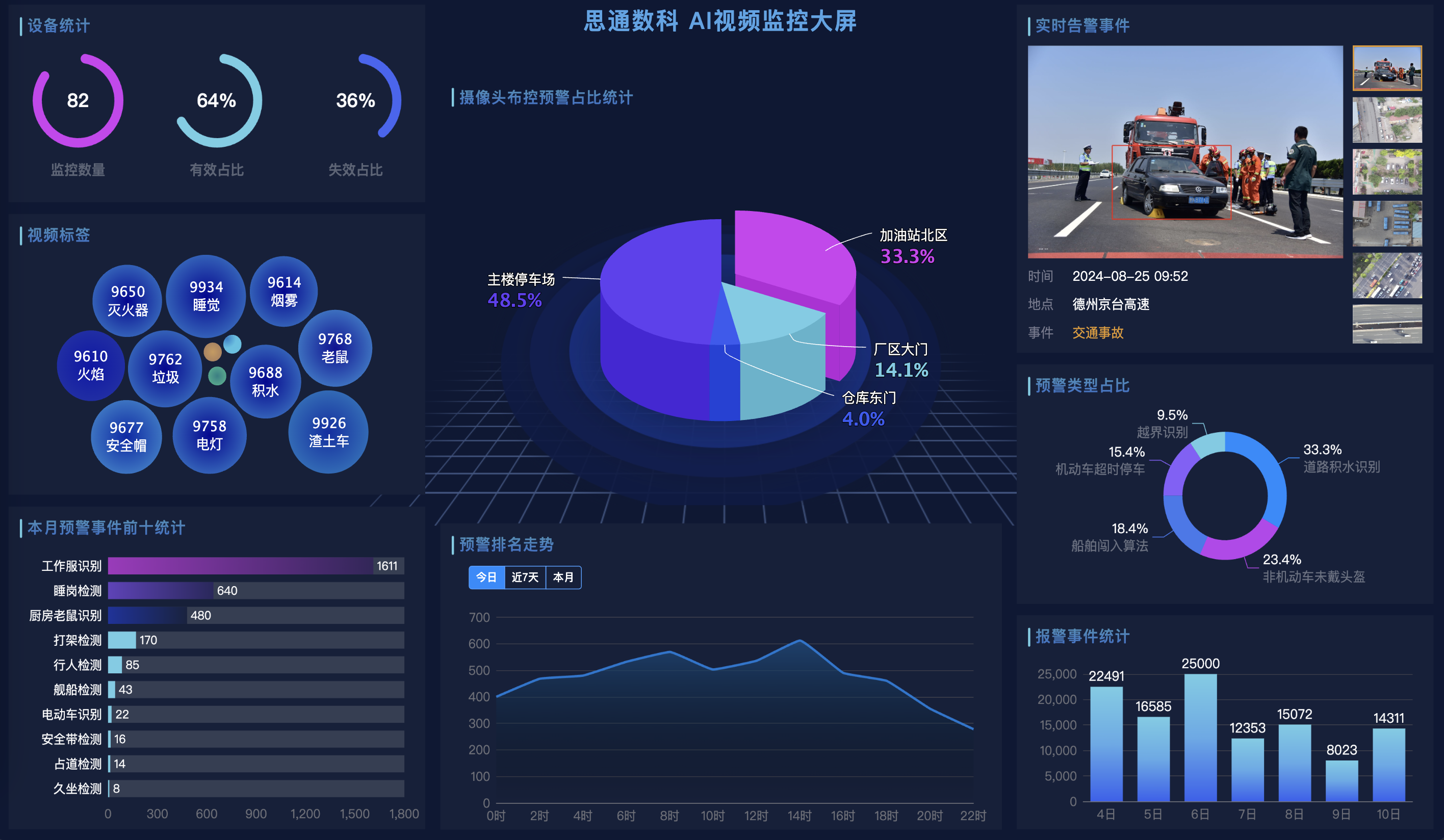
在建筑工地和其他劳动密集型行业,工人的安全一直是管理工作的重中之重。为了确保工地的安全管理更加高效和智能化,思通数科推出了AI视频监控卫士。通过人工智能技术,系统不仅能实时监控,还能自动识别工地现场的安全隐患,为工地管理者提供了强有力的支持 ......
随着社会环境的复杂化和人口密度的增加,公安部门面临的挑战日益严峻。思通数科的AI视频监控卫士通过智能化技术手段,为各类公安场景提供了高效、精准的监控解决方案,显著提升了公安部门的响应能力和工作效率。以下详细介绍系统在不同应用场景中的重要作用 ......
能源行业的安全与稳定运行对于社会的可持续发展至关重要,无论是石油、天然气还是电力设施,都面临着复杂的监测需求。思通数科推出的AI视频监控卫士,通过应用先进的人工智能技术,为能源行业的安全监测提供了高效、智能的解决方案。以下将详细介绍系统在油 ......
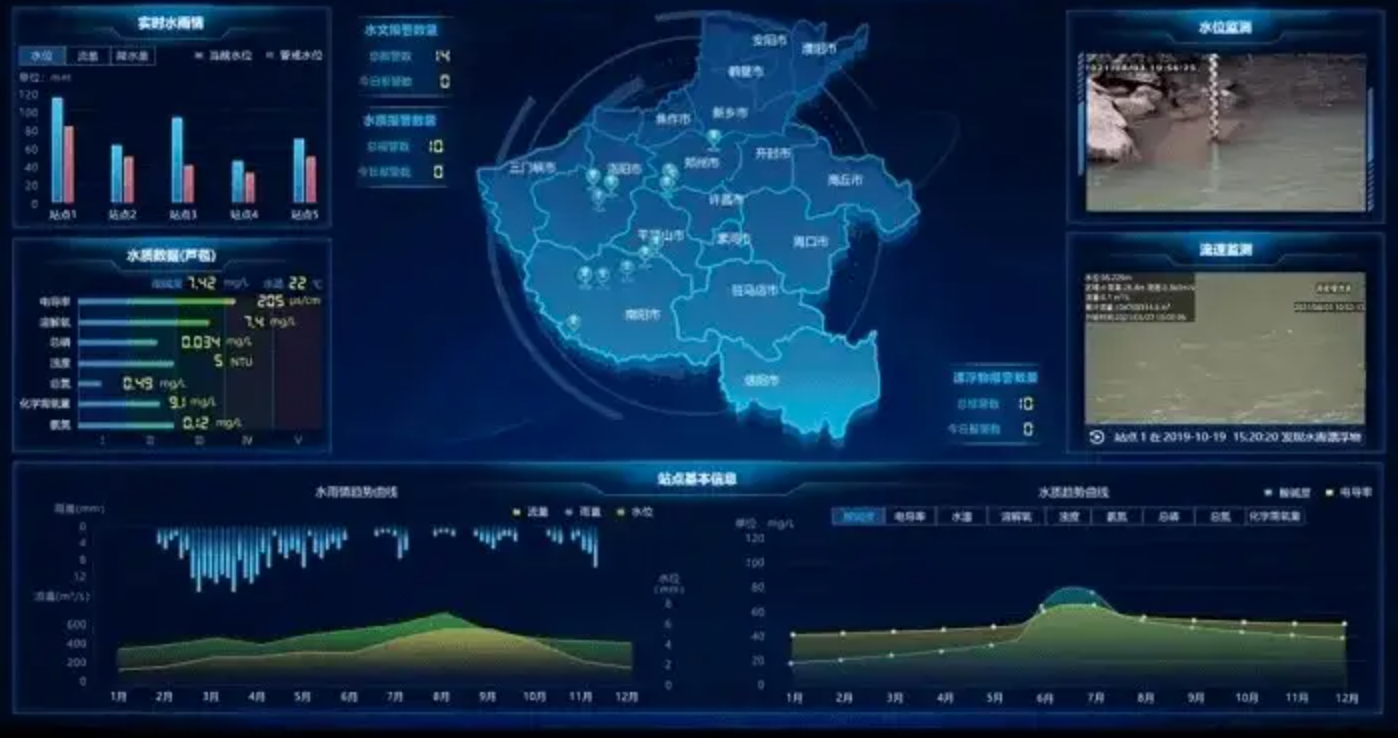
河道作为关键的自然水资源,其健康状况直接影响着生态环境和人类生活。传统的河道巡检依赖人工巡查,费时费力且难以做到实时覆盖。为了解决这一问题,思通数科推出的AI视频监控卫士,引入人工智能技术,为河道巡检提供高效、智能化的解决方案。本文将详细介 ......
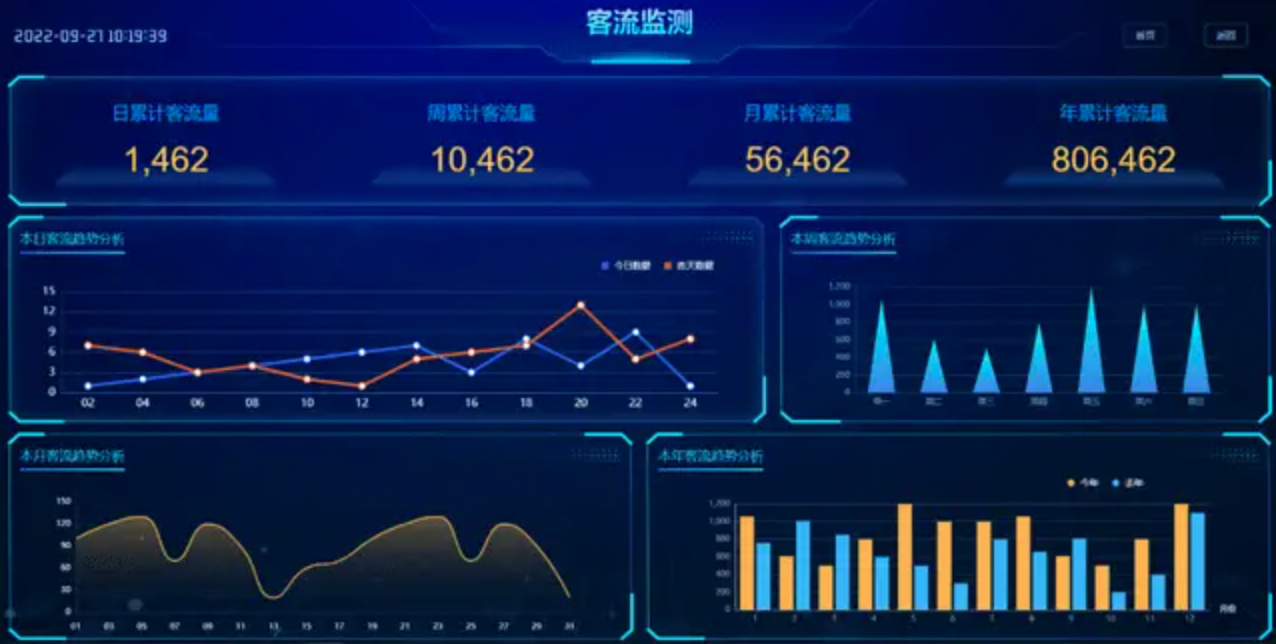
在人工智能技术的推动下,各行各业都在寻求通过AI实现业务的转型与升级。思通数科AI视频卫士,作为一套前沿的AI视频监控解决方案,正成为旅游景区景点安全监控转型过程中的重要助力。 1. 人流管理与安全防护 景区游客流量大且集中,思通数科AI视 ......
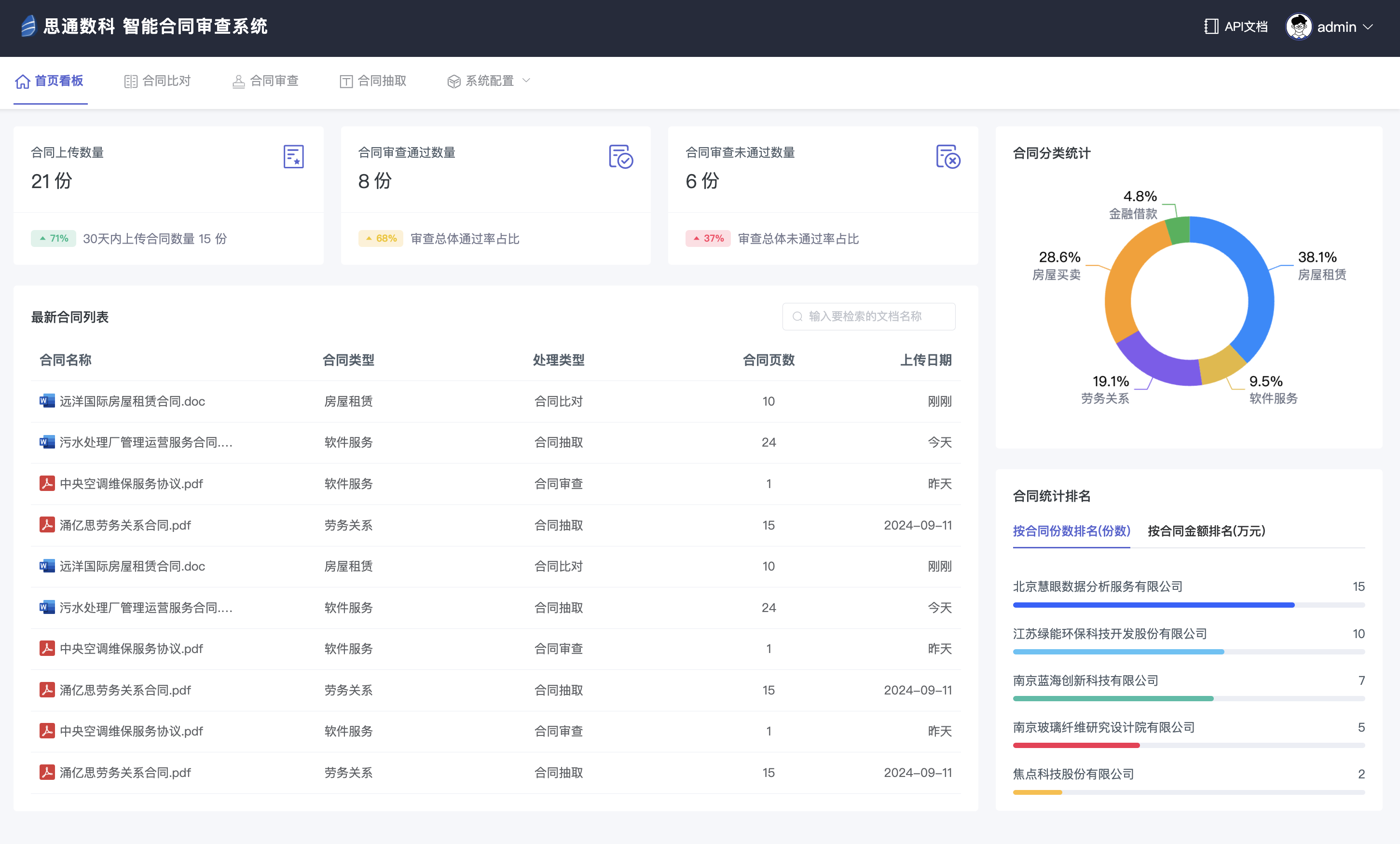
在当今商业环境中,合同管理是企业运营中的关键环节。随着业务的扩展,合同数量的增加,传统的人工审核方式已经难以满足高效、准确的管理需求。思通数科的智能文档处理平台通过先进的人工智能技术,提供了一种自动化、智能化的合同对比解决方案,极大地提高了 ......
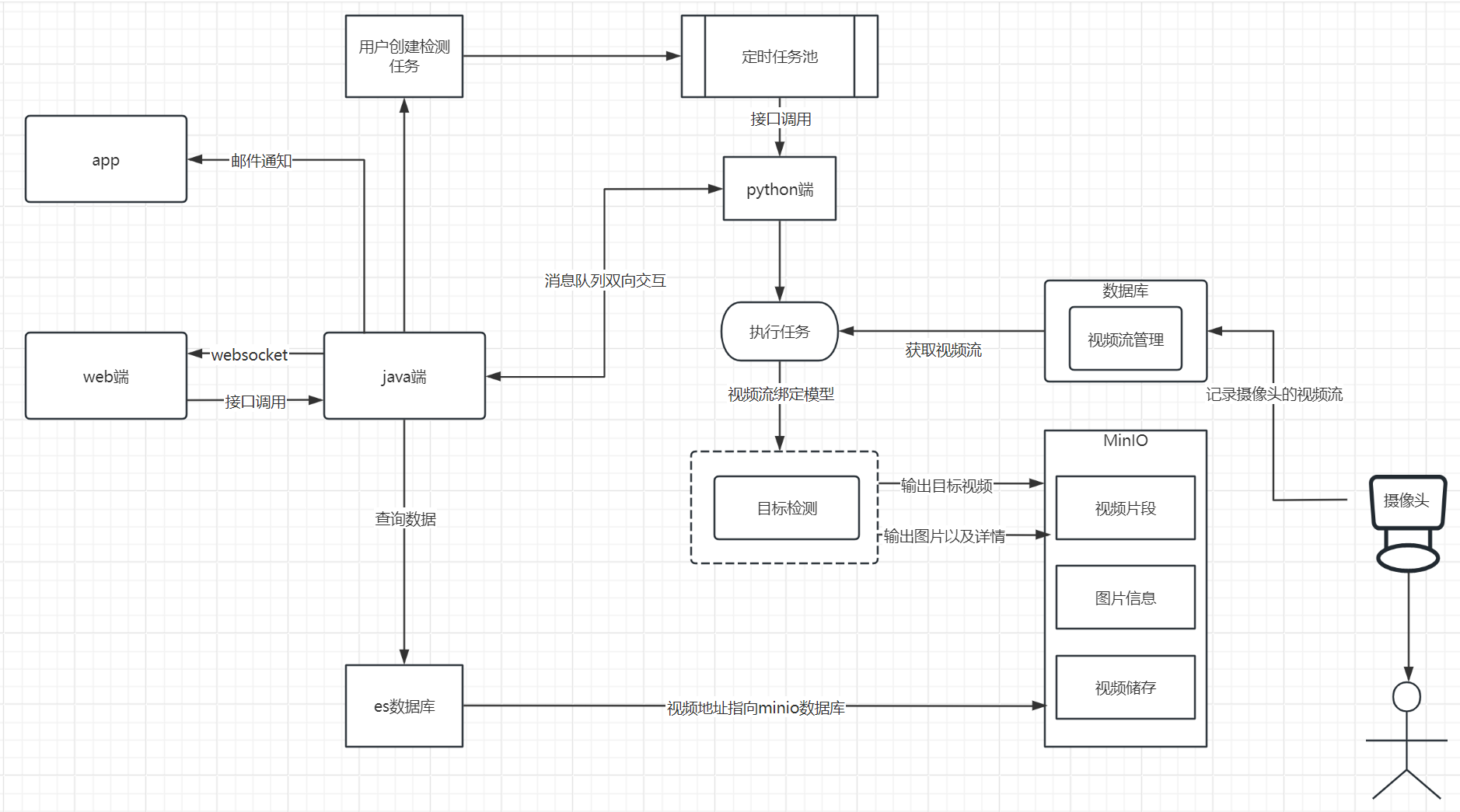
思通数科的AI视频监控卫士是一款集成了人工智能技术的先进视频监控解决方案。它通过结合机器学习算法和大数据分析,为用户提供了一个全面、自动化的视频监控系统。 AI视频监控卫士在化工场景的应用非常具体,主要体现在以下几个方面: 1.危险识别与预 ......
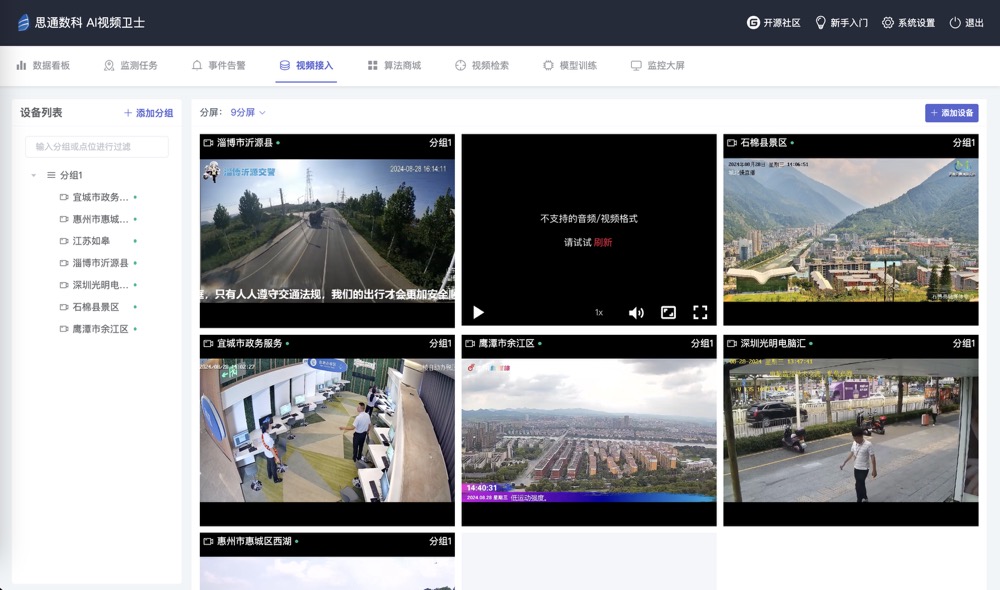
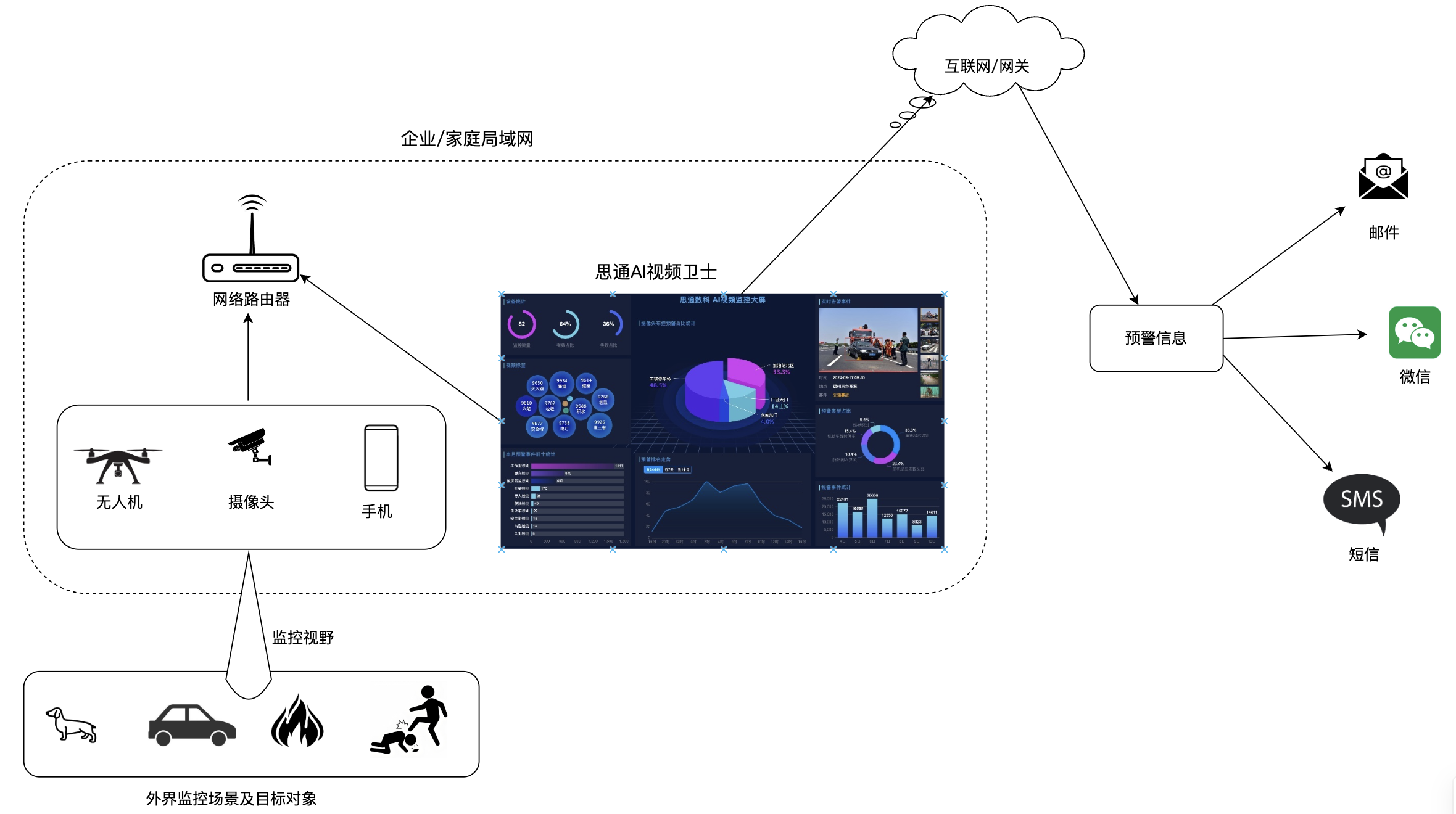
思通数科的AI视频监控卫士是一款功能强大的监控解决方案,适用于多种监控需求和场景: 1. 家庭安全监控: - 使用手机或支持RTSP的摄像头,用户可以实时监控家中情况,如照看老人、小孩或宠物,以及预防盗窃。 2. 企业安全监控: - 企业可 ......
摘要 用户只需要在手机上安装一款IP摄像头软件,通过这款软件与思通AI视频卫士——一个开源免费的AI视频监控系统连接,就能立马将手机变成一个能够识别万物的智能监控神器。无论是监控家庭安全、企业资产还是其他重要区域,这一系统都能提供实时的监控 ......
思通数科(南京)信息技术有限公司是一家专注于文本和影像数据的处理与理解的高科技企业,其核心业务是利用人工智能技术处理和提炼企业积累的海量结构化和非结构化文档,以帮助企业用户快速、高效、便捷地实现知识的获取、共享、应用和创新。通过自研的AI开 ......